
独家|DeepSeek 50亿起投,最新估值高达3000亿
独家|DeepSeek 50亿起投,最新估值高达3000亿一位接近DeepSeek的一线机构投资人士告诉我们,这些数字都不准确,DeepSeek融前估值是3000亿人民币,约合440亿美元。这一估值超过当前已经上市的大模型公司Minimax的2400亿(4月23日),接近智谱的3800亿元。
来自主题: AI资讯
8463 点击 2026-04-23 17:09
 搜索
搜索
一位接近DeepSeek的一线机构投资人士告诉我们,这些数字都不准确,DeepSeek融前估值是3000亿人民币,约合440亿美元。这一估值超过当前已经上市的大模型公司Minimax的2400亿(4月23日),接近智谱的3800亿元。

小米大模型时隔一月能力飙涨,比Kimi K2.6省42% Token。

大模型人才涌入,帮助智驾厂商突破原有技术框架上限。
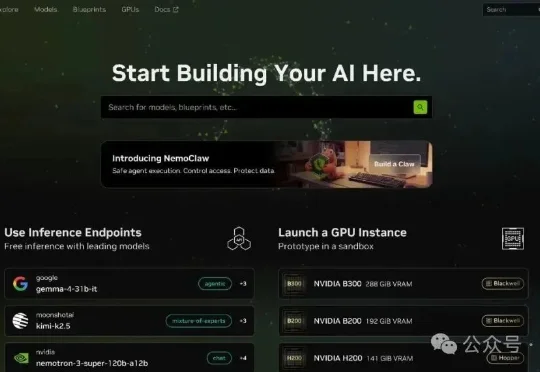
英伟达良心福利!免费领一年顶级大模型订阅,MiniMax / Kimi / DeepSeek 全都能用!NVIDIA 官方平台build.nvidia.com开放了一批"Free Endpoint"模型,注册账号、验证手机号后就能生成一把最长有效期12 个月的 API Key,免费调用几十个当下最火的大模型——不计 Token、无余额限制、无需信用卡。
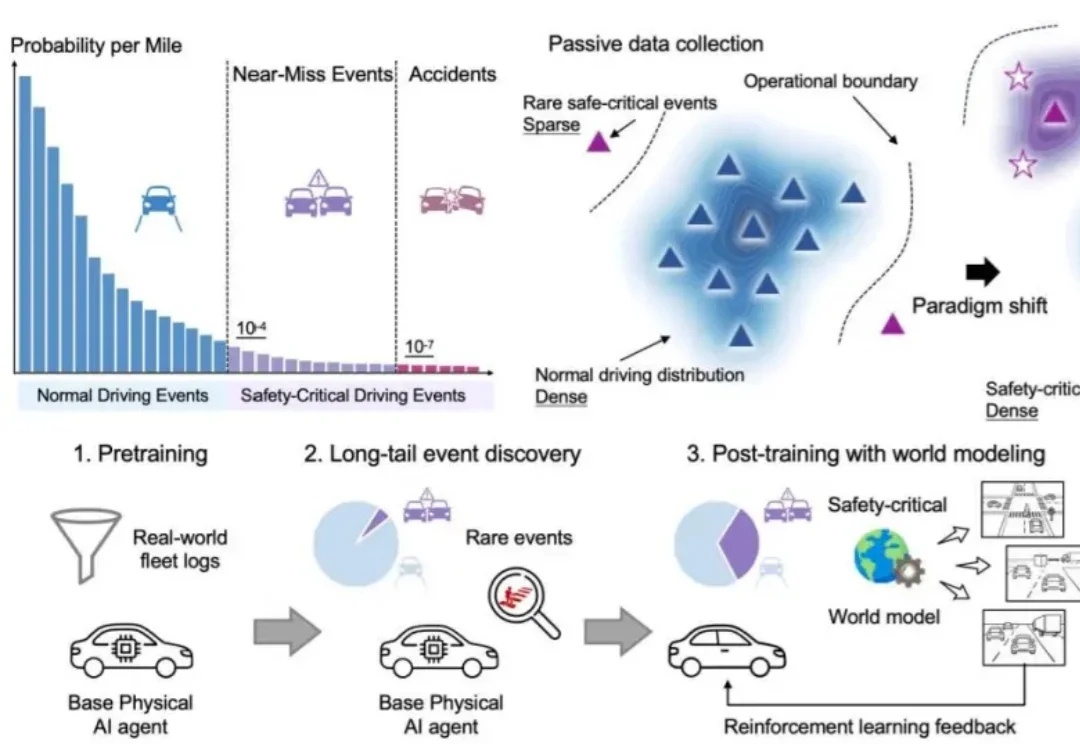
一年前,DeepSeek R1 横空出世,人们才意识到,真正让模型产生推理能力质变的,不必是更大的预训练规模 —— 后训练,用强化学习、过程奖励、闭环反馈,以极低的代价解锁了原本需要数倍算力才能触达的能力边界。
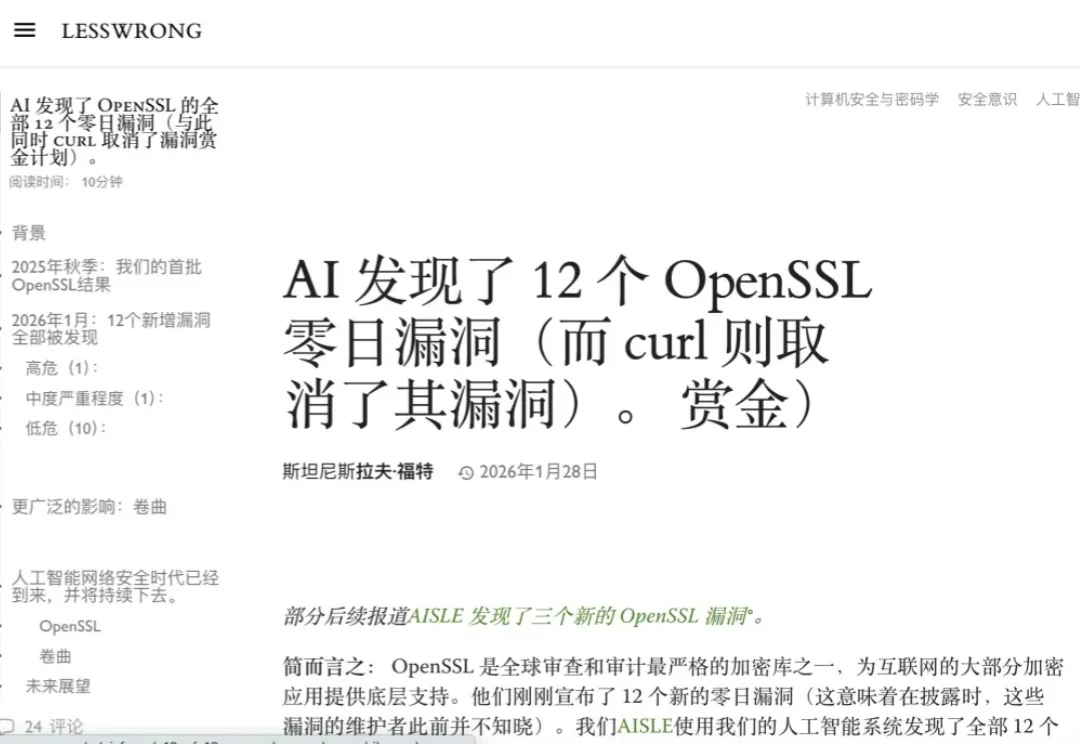
上周 Anthropic 发布 Mythos Preview 的时候,安全圈的反应可以用一个词概括:震惊。
不更是不更,一更就是个大动作,DeepSeek V4可能真的要来了!

就在大家都急头白脸地等待DeepSeek-V4的时候,冷不丁一篇新论文引起了网友们的注意—— 提出新稀疏注意力机制HISA(分层索引稀疏注意力),突破64K上下文的索引瓶颈,相比DeepSeek正在用的DSA(DeepSeek Sparse Attention)提速2-4倍。

ICLR论文STEM架构率先提出「查表式记忆」架构,早于DeepSeek Engram三个月。它将Transformer的FFN从动态计算改为静态查表,用token索引的embedding表直接读取记忆,彻底解耦记忆容量与计算开销。
从3月29日晚21时左右起,国内大模型产品DeepSeek的网页端与APP端服务器持续处于崩溃状态,大量用户反馈无法正常访问对话服务。